本日若干突破口が見えたので書きますかね。
さて、前回は動画を切り抜いてテキストボックスだけの画像を保存することができました。これをテキストデータにしたいと思います。画像から文字を認識してテキストに変換する技術はOCR (Optical character recognition) と呼ばれるやつですね。pythonの場合はTesseractというソフトをpyocrモジュールから使うのが普通みたいですね。
このTesseract(てっせらくと)が厄介でバージョンによってやれることが全然違います。
v3.0x系はjTessBoxEditorというソフトを組み合わせてフォントを使った学習ができます。フォントがインストールされていれば(全ユーザーに対するインストールが必要)画像作るところから学習データを作るところまでやってくれます。認識する画像にゴミを加えることもできる。
で、スキップEはほとんど上手く認識できたのですが何故かニタラゴルイカの認識が全然上手くいかず……。文字の種類が少なければ学習の回数を増やして精度を上げられるみたいだが、日本語だとそういう訳にもいかないし……。そう思うとアルファベットに対して漢字を含む日本語はOCRにおいて圧倒的なハンデ不利があるな……まぁ中国語に比べたらマシか……。
Tシャツに英語を書いてばっかの国みたいな話がありますが、日本語フォントがスタイリッシュになれないのはひらがなカタカナ漢字という全然形状の違う文字を含んでいる時点でもう全然まったくどうしようもないんだよな。勝てっこないのよ、アルファベットとか、アラビア語とか、あぁいう文字にさ。日本語のことは好きだが表記体系は好きじゃねぇ……。ちなみにTesseractの学習済みデータも日本語データには標準でアルファベットが入ってくる。入れないとまともに文章を識別できないもんな。すいませんね、お手数おかけしてね……。
話が逸れた。
それでニタラゴルイカが識別できなくてふてくされていたのですが一つ上のバージョンがあることを思い出しました。これが昨日。
v4.x系は安定バージョンの中では最新で、LSTMを使ったエンジンを搭載しています。響きがかっこいいですね。
LSTM (Long short-term memory) は自然言語処理モデルの一種で……私の理解するところで喋るとRNNの発展版で今まで入力された単語を適宜覚え適宜忘れながらも次にくる単語を予想するモデルです……。三ヶ月の付け焼き刃だからあまり突っ込まないでくれ。
要するにv3では文字を認識して一文字一文字テキストを認識していたのに対して、v4では読み取ったそれらをある程度固まった文章として認識して、自然な文章になるかどうかで文字認識の結果を調整……ということをしているんでしょう……おそらく……。
ただ問題はv4系ではフォントを使った学習ができないという点です。いや、正確にはあれ、Linux?あれを使えばできるっぽいんですけど、私はあれ系が全然できないのでできません。ターミナル、怖いよね。コントロールCが効かない時点でだいぶ怖い。
フォントのデータがあるんだから学習した方が精度いいに決まってると思っていたが盲点でしたね。フォントがせっかく手元にあったしね。使いたかったんだよね。わかるよ。
そういう訳でv4.1で試したら簡単でした。ニタラゴルイカの方はもう少し整形が必要そうなので(動画中でフェードアウトされたりするとフレーム抽出が厳しい)引き続きスキップEでいきましょう。
#モジュール呼び出し
from PIL import Image
from IPython.display import display_png
import pyocr
import pyocr.builders
import pprint
#OCR
def ocr(img, languages):
tools = pyocr.get_available_tools()
tool = tools[0]
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
txt = tool.image_to_string(img, lang=languages, builder = builder)
return txt
#フレーム抽出からOCRまで
def frame_ocr(frame_sel_list, c_max, language):
text_list = []
languages = language
for i in frame_sel_list:
temp = level_cor(i, c_max)
temp = pil_con(temp)
txt = ocr(temp, languages)
text_list.append(txt)
return text_list
OCR前にグレースケールをさらに白黒画像に変換してます。日本語学習データは2種類あるけど重いデータの方がいい訳ではないっぽい……。
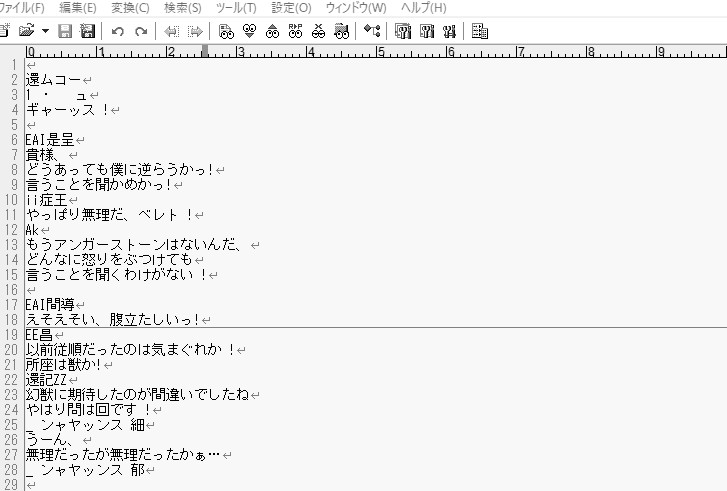
結果。
壊れたラジオになってる部分はキャラ名が出てるところなのでしょうがないですね。白抜きの上に影付きになっているからなんか別の画像処理が必要そう。
肝心の台詞部分は……うーん7割くらいはあってる……?スキップEはv3の方がいいかもな……。
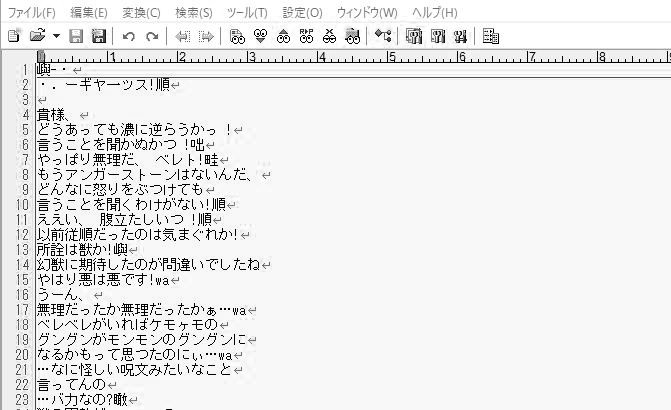
v3ではこんな感じ。
v4ではベレトの一人称が「僕」になってるのに対してv3は「濃」なのがそれぞれの特徴が出ていて面白いですね(本来は「儂」)。
これから調整はしますが大枠はできたということでよしとしましょう。
録画ファイル作るの面倒だな~。
参考文献