
ある日元気にソシャゲのオタクがはまったばっかりの時に作るメモを書いていました。
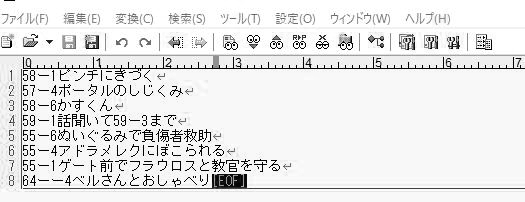
段々苛立ってきた。令和にもなってテキストを探すためになんでこんなことをやっているんだ?ロード時間、必死に記憶をたどってあちこちの章をうろうろする時間、話の冒頭だけチェックして→やっぱ違ったかも→いややっぱこの話の最後の方だわってやる時間。あ~全部無駄。
紙の本ってすごいな。テキストを大雑把に検索する方法って未だに紙の本が一番早い。シナリオ本が欲しい。次点でシナリオ検索ボックス。両方あるともっといい。ソーシャルゲームとしてのシナリオへの誠意……(「誠意」という言葉を私は世間で言う「愛情」のように容易に使いがちで宜しくないと思いますがここでいうシナリオへの誠意とはゲーム内でシナリオという要素が結局顧客の愛着、課金につながっていることを自覚した開発コストをかけろという要求を示しています)。しかし私は極めて理性的な人間なのでわかります。シナリオはゲームを起動させるためのインセンティブを担っているわけですよね。それからゲームのブランドとしてシナリオ本を出すためのコストも考慮しなければいけない。俺達は直打ちのtxtファイルでいいと言っても公式がそんなもの出すわけにはいかないんだ(でも突然WAVファイルを配布するゲームならワンチャンあるかもな)。
世は大自己責任時代。ソシャゲのユーザーも楽しみ方は自らで見いださなければならないとされる。
うーん、じゃあ自分でやるか。
オートモードで録画するとシナリオが動画として保存できるから、ここからテキストが抽出できればそれでいいだろう。本当は録画さえ面倒くさいがそこはもうどうしようもないので妥協しましょう。しかしシナリオのオート機能って到底人が読めない速さで流れていくけど、なんのための機能なんだろうね。もしかして公式としてテキスト抽出を推奨しているのかな?(自己の正当化)
#動画の切り出し
import cv2
import matplotlib.pyplot as plt
import numpy as np
import time
import winsound
def mov_info(cap):
print(“フレームレート(枚数/second)”, cap.get(cv2.CAP_PROP_FPS))
print(“フレーム枚数(枚数/second)”, cap.get(cv2.CAP_PROP_FRAME_COUNT))
print(“秒数”, cap.get(cv2.CAP_PROP_FRAME_COUNT)/cap.get(cv2.CAP_PROP_FPS))
(出力)
フレームレート(枚数/second) 29.74832623603263
フレーム枚数(枚数/second) 12819.0
秒数 430.915
まずはopencvで動画の情報を調べてみます。動画というのはパラパラ漫画です。このデータは430秒の動画が12819枚の画像で構成されているという訳だ。これを全部保存、閲覧するのは無駄なので、この中から必要な画像を抜き出していきます。
# movieのキャプチャを配列に変換
def mov_cap(capture, triming, grayscale, frame_sp):
frame_list = []
frame_del_list = []
frame_prev = []
framenum_prev = 0
counter = 0
frame_ls = list(np.arange(0, cap.get(cv2.CAP_PROP_FRAME_COUNT), frame_sp)) + [cap.get(cv2.CAP_PROP_FRAME_COUNT)]
while True:
ret, frame = capture.read()
if not ret:
break
frame = cv2.flip(frame, -1)
#グレースケール
if grayscale == True:
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
#トリミング
if triming == True:
frame = frame[y1:y2, x1:x2]
frame_list.append(frame)
#1個目でないなら差を計算してframe_del_listに追加
if frame_prev!=[]:
frameDelta = cv2.absdiff(frame_prev, frame)
frameDeltaSum = frameDelta
frame_del_list.append(frameDeltaSum)
frame_prev = frame
framenum_prev = cap.get(cv2.CAP_PROP_POS_FRAMES)
counter += 1
if counter >= len(frame_ls):
break
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_ls[counter])
return frame_list, frame_del_list
できた。
動画から切り出された画像は 縦ピクセル数×横ピクセル数×3(RとGとB)の数字の行列で表現されます(正確には配列という)。どんな神絵師の絵も配列だと思うと楽しいね。「人間は突き詰めればタンパク質の塊(もっと分解すればアミノ酸)」みたいなもん。
配列の操作は簡単です。まずはテキストボックスの座標を調べてトリミング。その後、RとGとBの値の平均を取ってグレースケールに変換。こうすると配列の長さと次元が減って軽くなる。そのあと、前フレームの画像の配列と今フレームの画像の配列を引き算して結果を保存。これで値が大きく動いた時に、テキストが切り替わったと判断できるというわけ。テキストボックスをトリミングしたのが効いてきて、動画の途中でソロモンが跳ねたりしてもテキストの動きだけ判断できるんですね。
差分をヒストグラムと時系列の折れ線グラフで図示してみます。
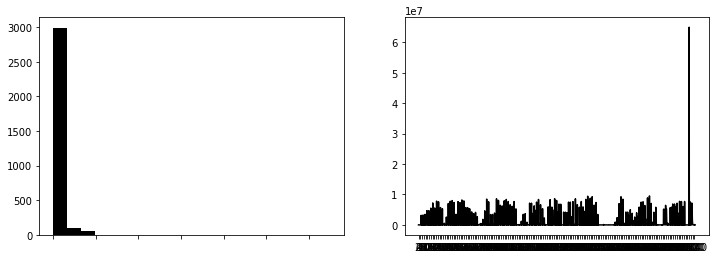
いいね。
ヒストグラムが0に寄っていることは動画がほとんど動いていないことを示しています。頻度ががくっと落ちているところを「動いた」の検出閾値とすればいい、と。
折れ線グラフは定期的に動画が動いていることを示しています。これを見ると約xxフレームでテキストが切り替わるようなので、全てのフレーム読み込む必要はなく、yyくらいの雑さでも問題ないことがわかります(パラメーターを書くとなんとなくよくなさそうなのでやってみたい人は自分で調べてみてね)。
#フレーム抽出用
start = time.time()
frame_list, frame_del_list = mov_cap(cap, triming, grayscale, frame_sp)
end = time.time()
t = time.time() – start
winsound.Beep(523, 1500)
print(t)
上で書いた関数をこんな感じで動かしてみる。2分くらいかかった。
Rを使っていた頃は時間がかかる処理が終わったあと電子レンジの音を鳴らしていたけどpythonになってエラーみたいな音しか鳴らせなくなっちゃった。通知音なんてなんでもいいと思ってたけどないと寂しいな。
#配列2種から大きく変化している画像のみを抽出
def frame_select(frame_list, frame_del_list, threshold):
frame_sel = [i for (i, j) in enumerate(frame_del_list) if np.sum(j) > threshold]
frame_sel_list = [j for i, j in enumerate(frame_list) if i in frame_sel]
return frame_sel_list
画像をダウンロードして見てみますか。
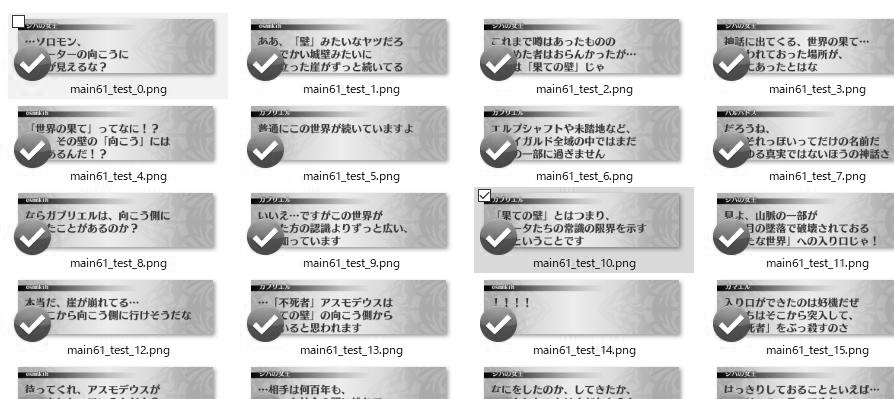
うんうん。
いいですね。一章で大体60MB、784枚か。画面がフェードアウトするところなんかでやや無駄な画像を保存している様子。これは閾値を上げても解決しなさそうなので許容としましょう。
これで終わりでもいいような気もするけど、検索の利便性のためにテキストファイルへの変換をやってみましょうかね。
次回に続く。
参考文献